👟 한걸음... 성장
드디어 설날을 뺀다 해도 3주간의 대장정이 끝났다............😥
설날이 중간에 있어서 휴식기간을 가졌음에도.... 너무나도 피폐해져가는 나날이었다.
이해도를 떠나서 수많은 오류 파도들이 내게 정면으로 쏟아져왔기에..
내가 이렇게 인내심이 있는 사람임을 비로소 느낀다... ㅎ
👟 그동안 배운것을 쭉 읊어본다면!
1. Elastic Stack
- Beats ( Filebeat, Metricbeat, Packetbeat )
- Logstash
- Elasticsearch
- Kibana
2. 분산 및 코디시스템
- Zookeeper
- Kafka
3. 실시간 처리 및 저장소
- Spark strure straming
- hadoop
👟 너무 광범위하게 배웠던 터라 엄청 걱정했던 시험
하지만 다행히도 조원들이랑 자료 공유하면서 다 맞았다 🙂
<총 2개 part 4문제씩>
1. 빅데이터에 대한 전반적인 틀
- 정의, 역할 등등
(추론...이란 키워드로 힌트를 주셨는데 사실은 그냥 문제를 읽으면 답이 보이는 문제!)
2. elasticsearch 문제
여기서 틀린 것이 logstash에 대한 설명으로 기억한다 ㅎ
*Elasticsearch
Elasticsearch는 시간이 갈수록 증가하는 문제를 처리하는 분산형 RESTful 검색 및 분석 엔진.
Elastic Stack의 중심으로, Elasticsearch는 손쉽게 확장되는 번개처럼 빠른 검색, 정교하게 조정된 정확도, 강력한 분석을 위해 데이터를 중앙에 저장합니다.숫자, 텍스트, 위치 정보, 정형 데이터, 비정형 데이터 등. Elasticsearch는 모든 유형의 데이터를 환영합니다. 전 세계의 기업들은 풀텍스트 검색 이외에도 다양한 문제 해결을 위해 Elasticsearch를 신뢰하고 있습니다
* Logstash
무료 오픈 소스 서버의 데이터 처리 파이프라인인 Logstash는 다양한 소스에서 데이터를 수집하여 변환한 후 자주 사용하는 저장소로 전달합니다.
광범위한 플러그인이 구비되어 다양한 아키텍처에서 손쉽게 데이터를 수집, 처리, 전달 가능. 프로세싱은 하나 이상의 파이프라인으로 구성. 각 파이프라인에서 하나 이상의 입력 플러그인이 내부 대기열에 배치된 데이터를 수신하거나 수집. 기본적으로 작고, 메모리에 보관되지만 안정성과 복원력을 향상시키도록 디스크에서 더 크고 영구적으로 구성 가능합니다. 다양한 데이터를 통합하고 정규화해서 필요한 부분의 데이터를 Filtering 및 Streaming.
3. 샤드 / 레플리카 개념에 대한 문제!
: 어디에서 사용되고 있는지? Elasticsearch에만 사용하고 있는 지 여러군데 사용하고 있는 개념을 알아두기
4. 데이터 수집관련 기술
RDB 데이터의 종류에 따른 구현 형태 및 연동 방법, 내부 처리 방법
* DBMS - DBMS에 저장된 데이터 - 소켓(mysql port 3306) - 저장
* 반정형 이진 파일 - 로그 형태로 센서, 서버 등 머신이 발생하는 데이터 - 스트리밍 -저장
* 비정형 이진 파일 - 텍스트 형태의 파일, 동영상 파일, 이미지 파일 - FTP(File Transfer Protocol) - 저장·파싱
* 스크립트 파일 - 웹 상에 html, xml, JSON 형태로 존재 - HTTP - 저장·파싱
*소켓(Socket) 통신으로 연동하는 DBMS 수집 방법
- 주로 DBMS에서 벤더가 제공하는 드라이버를 통해 데이터를 연동함
*스트리밍 방식으로 연동하는 로그 데이터, 센서 데이터 수집 방법
- 주로 시스템에서 발생하는 데이터
- 스트리밍 방식의 연동 방법 : TCP, 블루투스, RFID 등 여러 가지 통신 프로토콜이 존재함
*FTP 프로토콜을 사용하는 이진 파일 수집 방법
- 비정형 데이터를 수집할 때 필요한 방법
- 데이터 수집 후 수집한 데이터를 그대로 사용하는 경우도 있지만, 서비스 활용을 위해 데이터의 파싱이 필요함
*HTTP 프로토콜을 사용하는 스크립트 파일 수집 방법
- 수집기 내에서 활용 가능한 데이터의 형태로 파싱 처리 후 시스템에 저장
- 웹 상에 존재하는 데이터는 반정형 데이터로 존재하기 때문
5. Elasticsearch :
- Elasticsearch 데이터에 대한 이야기. 샤드 레프리카, 인덱스 다큐먼트
클러스트 기반으로 쿼리에 저장할떄 어떤 개념인지
※ 참고 페이지: https://esbook.kimjmin.net/03-cluster/3.2-index-and-shards
Elasticsearch 에서는 단일 데이터 단위를 도큐먼트(document) 라고 하며 이 도큐먼트를 모아놓은 집합을 인덱스(Index) 라고 합니다. 인덱스라는 단어가 여러 뜻으로 사용되기 때문에 데이터 저장 단위인 인덱스는 인디시즈(indices) 라고 표현하기도 합니다. 이 책에서는 데이터를 Elasticsearch에 저장하는 행위는 색인, 그리고 도큐먼트의 집합 단위는 인덱스 라고 하겠습니다.
인덱스는 기본적으로 샤드(shard)라는 단위로 분리되고 각 노드에 분산되어 저장이 됩니다. 샤드는 루씬의 단일 검색 인스턴스 입니다. Elasticsearch 는 검색을 위한 쿼리 기능을 제공합니다.
--> 위 내용을 정리해보자면! (PPT 내용)
- Cluster : 전체 데이터를 함께 보유하고 모든 노드에서 연합 인덱싱 및 검색 기능을 제공하는 하나 이상의 노드 모음
- Node : 클러스터의 일부이며 데이터를 저장하고 클러스터의 인덱싱 및 검색 기능에 참여하는 단일 서버
- Index : 다소 유사한 특성을 갖는 문서들의 집합
- Type : Index 내에서 하나 이상의 Type을 정의
- Document : Index를 생성 할 수 있는 기본 정보 단위, JSON표현
- Shards : shards를 이용하여 Index를 여러 조각으로 분할 가능, 기본 4개 제공
- Replication : 장애가 발생할 경우 고가용성을 제공, 기본 1개 제공
6. 시계열 데이터
- 빅데이터 활용 데이터 중 시계열 데이터의 정의, 역할 등
* 시계열 데이터란? 일정한 시간동안 수집 된 일련의 순차적으로 정해진 데이터 셋의 집합 입니다.
* 시계열 데이터의 분석 목적은 시계열이 갖고 있는 법칙성을 발견해 이를 모형화하고, 또 추정된 모형을 통하여 미래의 값을 forecasting(예측) 하는 것입니다.
* 시계열 데이터의 특징으로는 시간에 관해 순서가 매겨져 있다는 점과, 연속한 관측치는 서로 상관관계를 갖고 있습니다.
7. Rest api
Elasticsearch는 REST (Representational State Transfer) API를 제공하여 다양한 환경에서 사용 가능하기에 Rest 메서드 관련한 문제가 나왔다!
*Rest API란? REST에서 Methods의 주요 용도
- POST : 등록 (Create)
- PUT : 수정 (Replace), 데이터가 없을 경우에는 등록 (Create)
- DELETE : 삭제 (Delete)
- GET : 조회 (List, Retrieve)
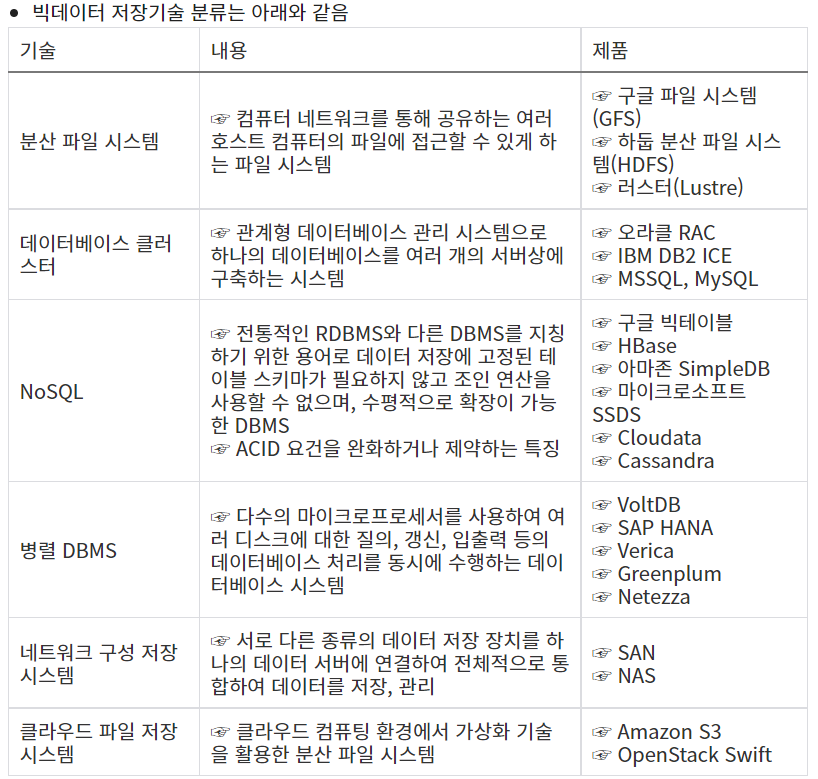
8. 빅데이터 저장에 필요한 기술
👟 후기
지금까지 배웠던 스킬을 내 것으로 소화시키기 위해 따로 독학을 해야할 것 같다!
엘라스틱관련한 책을 도서관에서 찾아봐야지! 끄-----읏!
앞으로 미니프로젝트와 산학프로젝트를 위한 그림을 그려봐야지!
'😏 K디지털트레이닝(KDT)' 카테고리의 다른 글
| [9주차] 🖥Power BI 수업 즐기기.....ㅋㅋㅋ (0) | 2022.03.08 |
|---|---|
| [8주차] 🖥️데이터 EDA (Pandas, Matplotlib, Seaborn) 수업 & 시험 (0) | 2022.02.25 |
| [개인과제] 빅데이터 플랫폼 개인과제 몰아서 해치우기! (0) | 2022.02.06 |
| [5주차] 빅데이터 플랫폼 중간 점검! 😙 (0) | 2022.02.06 |
| [4주차] 🖥️ 빅데이터 이슈 및 성공 / 빅데이터 플랫폼 (너무너무 좋았던 주차) (0) | 2022.02.01 |