
🤸 머신러닝 알고리즘 평가 🤸
1. Bias / Error
1) Bias
* Fitting: 실제값을 지나는 여러 개의 곡선이 존재
* 검증용 데이터를 고려한다면? Goodness of Fit

2) Error
① 과대적합(Overfitting): 모델이 훈련 데이터에 너무 잘 맞지만 일반성이 떨어질 때 발생
- 과대적합 해결방법: 훈련데이터를 더 많이 모은다. / 정규화시킨다. / 훈련데이터 잡음을 줄인다.
② 과소적합(Underfitting): 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 발생
- 과소적합 해결방법: 파라미터가 더 많은 복잡한 모델을 선택한다. / 모델의 제약을 줄인다(=규제 하이퍼파라미터 값 줄인다.) / 과대적합 되기 전의 시점까지 충분히 학습한다.
- 하이퍼파라미터란 학습하는 동안 적용할 규제(과대적합 되지 못하도록 제약)의 양을 결정하는 것이다. 너무 높으면 과소적합 문제 발생

2. 머신러닝 평가 데이터 구성
1) 학습 / 검증 / 테스트 데이터 분리
① 학습 데이터 (train data) : 모형 f 를 추정하는 데 필요합니다.
② 검증 데이터 (validation data ): 추정한 모형 f 가 적합한지 검증합니다.
③ 테스트 데이터 :(test data) : 최종적으로 선택한 모형의 성능을 평가합니다.

2) 교차검증
- 교차 검증은 train set을 train set + validation set으로 분리한 뒤, validation set을 사용해 검증하는 방식이다.
- 종류: K-Fold Cross Validation ( k-겹 교차 검증 ), Stratified K-Fold Cross Validation ( 계층별 k-겹 교차 검증 )

3. 모델 성능 측정
: 모델의 일반화 성능을 평가할 기준

4. 분류모델 평가지표

1) 정오분류표(Confusion Matrix)

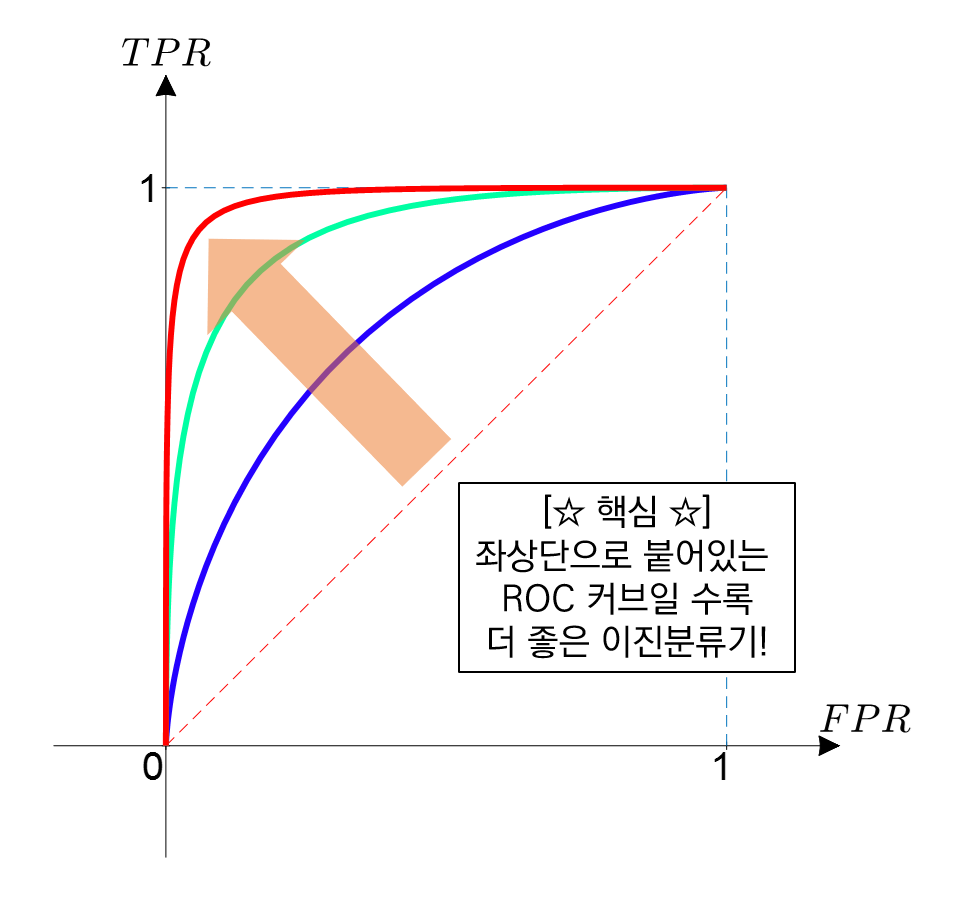
2) ROC (Receiver Operating Characteristic)
- 기준값(threshold)이 달라짐에 따라 분류모델의 성능이 어떻게 변하는지를 나타내기 위해 그리는 곡선
- 민감도를 y축에 놓고 (1-특이도)를 x축에 놓은 뒤 각 기준값(threshold)의 변화에 따라 성능 평가 지표의 값이 어떻게 변하는지를 시각화한 곡선
5. Variance / Bias
: 편향-분산 트레이드오프 (Bias-Variance Trade-off)는 지도 학습(Supervised learning)에서 error를 처리할 때 중요하게 생각해야 하는 요소이다!


'😆 Big Data > - ML & DL' 카테고리의 다른 글
| [ML]🚶♀️Simple salary data로 ML warm-up하기 (0) | 2022.03.15 |
|---|---|
| [ML] 🤸 5. 피처 엔지니어링 (Feature Engineering) (0) | 2022.03.01 |
| [ML] 🤸 3. 머신러닝 알고리즘 (0) | 2022.03.01 |
| [ML] 🤸 2. 머신러닝 데이터의 유형 (0) | 2022.03.01 |
| [ML] 🤸 1. 머신러닝의 개요 (0) | 2022.03.01 |