
'ADsP 예상문제 3과목 - 2 영상' 공부하기
Q15. 데이터 전처리 - 스케일링
- Min-Max Nomalization: 데이터 전처리 방법 중 데이터를 일정범위로 Feature scaling 범위 0~1사이로 적용해주고 원 데이터 분포를 유지하는 정규화 방법
- Standardization: 평균 0, 표준편차 1인 표준 정규분포를 변환하는 것
Q16. 결측값(missing value)처리에 대한 대치법

- complete case analysis: 결측값은 삭제. 불완전 자료는 모두 무시하고 완전하게 관측된 자료만으로 표준적 통계기법에 의해 분석하는 방법
- 평균대치법(mean imputation): 관측/실험결과자료의 적절한 평균값으로 결측값 대치하여 완전한 자료로 만든 후,--> 완전한 자료를 마치 관측/실험결과자료라고 생각하고 분석하는 방법
- 단순 확률 대치법(single stochastic imputation)은 평균대치법에서 추정량 표준오차의 과소추정문제를 보완
- 다중대치법: 단순 대치법을 한번이 아닌 m번 수행하여 m개의 가상적 완전자료를 만듦. 추정량 표준오차의 과소추정 또는 계산의 난해성 문제를 가지고 있음
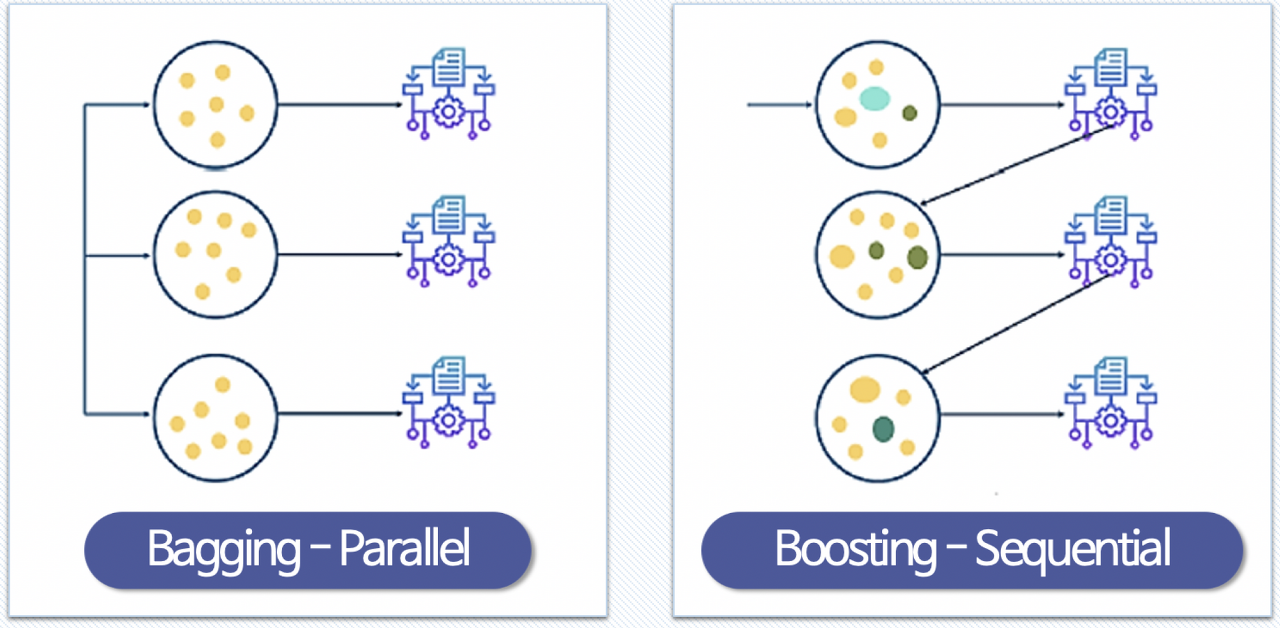
Q17. 앙상블 모형
- 배깅(Bagging)
- 랜덤 포레스트(Random Forest)
- 부스팅(Boosting)
Q18. 계층적 군집(Hierarchical Clustering) - 응집형(병합) 군집 방법
- 최단연결법, 최장연결법, 중심연결법, 와드연결볍, 평균연결법
Q19. 통계적추론 - 가설검정
- 모집단에 대한 어떤 가설을 설정한 뒤에 표본관찰을 통해 그 가설의 채택여부를 결정하는 분석방법
- 표본관찰 또는 실험을 통해 귀무가설과 대립가설 중에서 하나를 선택하는 과정
- 귀무가설이 옳다는 전제하에 검정통계량 값을 구한 후에 이 값이 나타날 가능성의 크기에 의해 귀무가설의 채택여부를 결정
| 귀무가설 [Null Hypothesis, H0] |
현재까지 주장되어온 것이나 변화나 차이가 없음을 설명하는 가설 |
| 대립가설 [Alternative Hypothesis, H1] |
귀무가설에 반대되는 주장을 하는 가설로 귀무가설을 기각했을 때 받아들여지는 가설 실제 검정대상이 되는 가설은 아니다! |
| 검정통계량 [Test Statistic] |
관찰된 표본으로부터 구하는 통계량 검정 시 가설의 진위를 판단하는 기준 |
| 유의수준 [Significance Level, α] |
귀무가설을 기각하게 되는 확률의 크기로 '귀무가설이 옳은데도 이를 기각하는 확률의 크기' |
| 유의확률 [p-value] |
귀무가설이 맞다고 정할 때, 표본통계량보다 극단적인 결과가 실제로 관측될 확률 (귀무가설이 사실일 때 기각하는 1종 오류 시 우리가 내린 판정이 잘못되었을 확률) p-value와 α를 비교하여 귀무가설 기각 여부를 결정[p-value<α이면 기각] |
| 기각역 [Critical Region,C] |
귀무가설을 기각시키는 검정통계량들의 범위[반대는 채택역(acceptance region)} 귀무가설이 옳다는 전제 하에서 구한 검정통계량의 분포에서 확률이 유의수준 α인 부분 |
* 제1종오류 & 제2종오류
| H0가 사실이라고 판정 | H0가 사실이 아니라고 판정 | |
| H0가 사실임 | 옳음 결정 | 제 1종 오류[α] |
| H0가 사실이 아님 | 제 2종 오류[β] | 옳은 결정 |
- 제 1종 오류[Type 1 error] : 귀무가설 H0가 옳은데도 귀무가설을 기각하게 되는 오류
- 제 2종 오류[Type 2 error] : 귀무가설 H0가 옳지 않은데도 귀무가설을 채택하게 되는 오류
Q21. 다중공선성
- 독립변수간 상관관계까 높아 많은 문제점을 발생하는 현상으로 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만드는 것
- 모형의 일부 설명변수(=예측변수)가 다른 설명변수와 상관되어 있을 때 발생하는 조건
- 중대한 다중공선성은 회귀계수의 분산을 증가시켜 불안정하고 해석하기 어렵게 만들기 때문에 문제가 됨
Q24. 연관분석
- 연관규칙은 항목들 간의 '조건-결과'식으로 표현되는 유용한 패턴이다
- 장바구니 분석이라고도 하고, Apriori알고리즘과 FP Growth가 대표적이다
- 연관규칙 측정지표에는 지지도 신뢰도 향상도가 있다.
Q26. 오분류표 - 특이도
- 실제도 Negative(-)인 것들 중 예측이 Negative(-)으로 된 경우의 비율
- TN / (TN+FP)
Q28. 오즈( Odds)
- 로지스틱 회귀분석에서 exp(x1)의 의미는 x1이 한 단위 증가할 때마다 성공의 오즈(Odds)가 몇 배 증가하는 지 나타냄
Q29. 시계열자료
- 정상성(Stationary)란? 시계열 분석에서 시계열의 수준과 분산에 체계적인 변화가 없고, 주기적 변동이 없는 것으로 미래는 확률적으로 과거와 동일함을 뜻한다.
Q30. 연관규칙 - Apriori
- 연관규칙 분석기법의 대표적 알고리즘
- 가장 빈번한 항목 집합을 찾기 위한 접근 방식(발생빈도를 기반으로 연관관계를 밝힘)
- 이해하기 쉽고 전체 데이터를 스캔한다.
- 데이터셋이 큰 경우 모든 후보 itemset에 대해 하나하나 검사하는 것이 비효율적
+ FP Growth: Apriori 단점을 보완하기 위해 FP-tree와 node, link라는 특별한 자료 구조를 사용한다.
'😆 Big Data > - 데이터' 카테고리의 다른 글
| 데이터 분석 고도화를 위한 데이터 전처리 관련 자료 모아보기 (0) | 2022.07.04 |
|---|---|
| [Power BI] 📊 1. Power BI 살펴보기 (0) | 2022.03.02 |
| [ADsP] ADsP 예상문제 3과목 - 1 영상 공부하기 (0) | 2022.02.25 |
| [ADsP] ADsP 예상문제 3과목 - 4 영상 공부하기 (0) | 2022.02.24 |
| [ADsP] ADsP 예상문제 3과목 - 3 영상 공부하기 (0) | 2022.02.24 |