728x90

부스트코스 - '모두를 위한 데이터 사이언스' 강의를 참고로 만들어 본 자동차 연비예측하기!
텐서플로를 통한 자동차 연비 예측하기¶
In [21]:
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
#티스토리 업로드 원활하게:-)
필요 도구 가져오기¶
In [1]:
# 데이터 분석을 위한 pandas, 시각화를 위한 seaborn 불러오기
import pandas as pd
import seaborn as sns
데이터셋 로드¶
In [2]:
# 자동차연비 데이터셋인 mpg 데이터셋을 불러옵니다.
df = sns.load_dataset("mpg")
df.shape
Out[2]:
(398, 9)결측치 확인¶
In [3]:
# 결측치의 합계 구하기
df.isnull().sum()
Out[3]:
mpg 0
cylinders 0
displacement 0
horsepower 6
weight 0
acceleration 0
model_year 0
origin 0
name 0
dtype: int64결측치 제거¶
In [4]:
# dropna로 결측치를 제거합니다.
df = df.dropna()
df.shape
Out[4]:
(392, 9)수치 데이터만 가져오기¶
- 머신러닝이나 딥러닝 모델은 내부에서 수치계산을 하기 때문에 숫자가 아닌 데이터를 넣어주면 모델이 학습과 예측을 할 수 없습니다.
In [5]:
# select_dtypes 를 통해 object 타입을 제외하고 가져옵니다.
df = df.select_dtypes(exclude="object")
df.shape
Out[5]:
(392, 7)전체 데이터에 대한 기술 통계 확인¶
In [6]:
# describe 를 통해 기술 통계값을 확인합니다.
df.describe(include="all")
Out[6]:
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | |
|---|---|---|---|---|---|---|---|
| count | 392.000000 | 392.000000 | 392.000000 | 392.000000 | 392.000000 | 392.000000 | 392.000000 |
| mean | 23.445918 | 5.471939 | 194.411990 | 104.469388 | 2977.584184 | 15.541327 | 75.979592 |
| std | 7.805007 | 1.705783 | 104.644004 | 38.491160 | 849.402560 | 2.758864 | 3.683737 |
| min | 9.000000 | 3.000000 | 68.000000 | 46.000000 | 1613.000000 | 8.000000 | 70.000000 |
| 25% | 17.000000 | 4.000000 | 105.000000 | 75.000000 | 2225.250000 | 13.775000 | 73.000000 |
| 50% | 22.750000 | 4.000000 | 151.000000 | 93.500000 | 2803.500000 | 15.500000 | 76.000000 |
| 75% | 29.000000 | 8.000000 | 275.750000 | 126.000000 | 3614.750000 | 17.025000 | 79.000000 |
| max | 46.600000 | 8.000000 | 455.000000 | 230.000000 | 5140.000000 | 24.800000 | 82.000000 |
데이터셋 나누기¶
In [7]:
# 전체 데이터프레임에서 df, train, test를 분리합니다.
# train_dataset : 학습에 사용 (예: 기출문제)
# test_dataset : 실제 예측에 사용 (예 : 실전문제)
# 기출문제로 공부하고 실전 시험을 보는 과정과 유사합니다.
train_dataset = df.sample(frac=0.8, random_state=42)
train_dataset.shape
Out[7]:
(314, 7)In [8]:
#train_dataset과 test_dataset의 인덱스가 겹칠 수 있으니 번호제거를 해준다
test_dataset = df.drop(train_dataset.index)
test_dataset.shape
Out[8]:
(78, 7)In [9]:
# train_dataset, test_dataset 에서 label(정답) 값을 꺼내 label 을 따로 생성합니다.
# 문제에서 정답을 분리하는 과정입니다.
# train_labels : train_dataset(예: 기출문제) 에서 정답을 꺼내서 분리합니다.
# test_labels : test_labels(예: 실전문제) 에서 정답을 꺼내서 분리합니다.
train_labels = train_dataset.pop("mpg")
train_labels.shape
Out[9]:
(314,)In [10]:
test_labels = test_dataset.pop("mpg")
test_labels.shape
Out[10]:
(78,)In [11]:
train_dataset.shape, test_dataset.shape
Out[11]:
((314, 6), (78, 6))딥러닝 모델 만들기¶
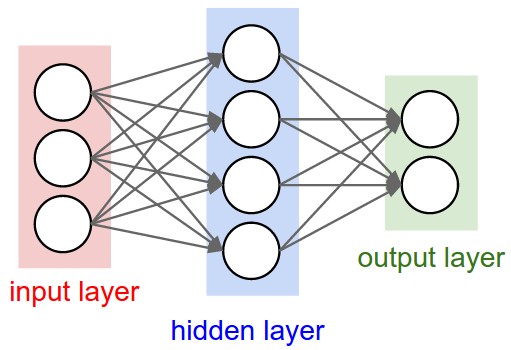

- 이미지 출처 : https://cs231n.github.io/neural-networks-1/
- 두 개의 완전 연결(densely connected) 은닉층으로 Sequential 모델을 만들겠습니다.
- 출력 층은 하나의 연속적인 값을 반환합니다.
In [12]:
# tensorflow 를 불러옵니다.
import tensorflow as tf
tf.__version__
Out[12]:
'2.7.0'딥러닝 층 구성¶
In [13]:
model = tf.keras.Sequential()
#유닛의 개수는 64로 임의로 정하기
#input_shape은 입력하는 변수의 개수
model.add(tf.keras.layers.Dense(64, activation="relu", input_shape=[len(train_dataset.keys())])),
model.add(tf.keras.layers.Dense(64, activation="relu")) #hidden
model.add(tf.keras.layers.Dense(64, activation="relu")) #hidden
model.add(tf.keras.layers.Dense(1))
모델 컴파일¶
In [14]:
#회귀모델에서 정확도를 측정하는 도구로 mae,mse 사용
#평균제곱오차(mean square error=mse)를
#평균절대오차(mean absolute error=mae): 예측과 타깃 사이 거리의 제곱
model.compile(loss="mse", metrics=["mae","mse"])
만든 모델 확인하기¶
In [15]:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 448
dense_1 (Dense) (None, 64) 4160
dense_2 (Dense) (None, 64) 4160
dense_3 (Dense) (None, 1) 65
=================================================================
Total params: 8,833
Trainable params: 8,833
Non-trainable params: 0
_________________________________________________________________
딥러닝 모델로 학습하기¶
In [16]:
#학습하는 횟수는 epochs
model.fit(train_dataset, train_labels, epochs=100, verbose=0)
Out[16]:
<keras.callbacks.History at 0x7f3924fffed0>딥러닝 모델로 평가하기¶
In [17]:
model.evaluate(test_dataset, test_labels)
#mae 값(오차값)이 0이 될수록 좋다
3/3 [==============================] - 0s 4ms/step - loss: 158.2999 - mae: 11.0054 - mse: 158.2999
Out[17]:
[158.2999267578125, 11.005400657653809, 158.2999267578125]딥러닝 모델의 예측하기¶
In [18]:
predict_labels = model.predict(test_dataset).flatten() #flatten()으로 1차원으로 볼수있게 함
predict_labels[:5]
Out[18]:
array([10.21708 , 11.183176, 15.921473, 14.157125, 10.307833],
dtype=float32)딥러닝 모델의 예측결과 평가하기¶
In [19]:
sns.scatterplot(x=test_labels, y=predict_labels)
Out[19]:
<matplotlib.axes._subplots.AxesSubplot at 0x7f392357a950>
In [20]:
sns.jointplot(x=test_labels, y=predict_labels, kind="reg")
Out[20]:
<seaborn.axisgrid.JointGrid at 0x7f3924de6910>
728x90
'😆 Big Data > - ML & DL' 카테고리의 다른 글
| [ML] 🤸 1. 머신러닝의 개요 (0) | 2022.03.01 |
|---|---|
| [ML 알고리즘] 이상 탐지(Anomaly Detection) 알고리즘 (0) | 2022.02.06 |
| [머신러닝] sklearn 로 붓꽃(아이리스) 품종 분류하기(사이킷런) (0) | 2021.12.23 |
| [inflearn] 파이썬 기초 라이브러리부터 쌓아가는 머신러닝 -2 (0) | 2021.11.23 |
| [inflearn] 파이썬 기초 라이브러리부터 쌓아가는 머신러닝 -1 (0) | 2021.11.22 |